

Shaping voices: Crafting expressive audio
Great videos start with great voices. Our Mirage audio model generates expressive, compelling vocal performances that elevate what’s possible for video.
“Words mean more than what is set down on paper. It takes the human voice to infuse them with shades of deeper meaning.”—Maya Angelou, I Know Why the Caged Bird Sings
Video with a voice
At Mirage, our mission is to build technology and products that enable anyone to go from zero to video, no matter their skill level or background. “Video” may sound simple on the surface, but its true meaning includes the promise of a full, engrossing audiovisual experience.
In our 2025 research report Seeing Voices, we introduced Mirage video, an audio-to-video model that generates realistic, expressive A-roll videos. Mirage video transforms expressive audio performances into fully realized videos of emotive, realistic people, but it relies on the user to provide evocative and persuasive audio input. This can be challenging: most people aren’t trained performers, and even pros can spend a lot of time trying to get the right vocal delivery. That’s why we’re introducing Mirage audio, a model that generates compelling audio performances from the ground up.
Real, transportive performances start with an expressive voice. Mirage audio generates performances that sound and feel like they’re delivered by real people in real places. By letting users create and shape these voices, we give access to a full world of audio-video performances to help them communicate their message.
From seeing voices to shaping voices
Theorists and practitioners of acting from Konstantin Stanislavski to Daniel Day-Lewis have noted the critical importance of the voice in producing specific and affecting performances. The relationship between vocal delivery and perceived authenticity extends to use cases like marketing, thought leadership, and business communication, where the voice is a primary driver of credibility, engagement, and persuasion. In our work on audiovisual generation, we have observed that the authenticity and expressivity of the vocal input heavily constrains the authenticity and expressivity of the resulting video:
Expressive audio
Monotone audio
The pacing and dynamics of an expressive audio performance lead to expressive gestures and movements in the visual performance.
We can think of each performance as consisting of the audio a, and the corresponding video v, as generated from a script text t (what is to be said) and other user controls c (which may include descriptions of the desired performance, reference audio, reference images, and other signals). With the Mirage family of models, we formulate the problem of modeling expressive performances as first mapping text to audio and then mapping audio to video, given the script and user controls:
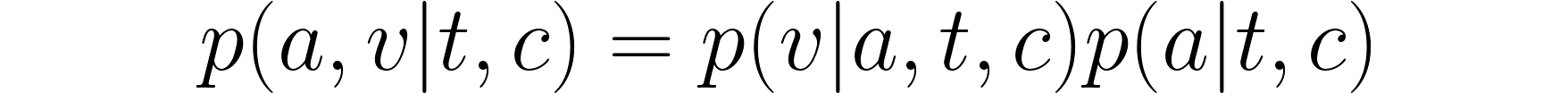
This formulation captures the observation that certain scripts are most naturally transformed to audio in certain ways, via p(a | t, c). Consider, for example, a performance for a product demo, which might sound like this:
Compare this to the same voice performing a monologue from a horror movie:
Or the same voice performing a nursery rhyme:
On the other hand, text is naturally consistent with many deliveries, each with varying subtext (the nuances that every speaker adds that makes text feel like a fleshed-out performance). When talking about a bad day, a speaker may focus on the frustration they experienced:
Or they may focus on the relief they felt that the day is over:
Because we trained the Mirage audio model to take an explicit description of the desired performance as well as the script, users can shape and sample the voice to match their message, even in the subtle details of its subtext.
Given the text and any conditioning, we sample full audiovisual performances in a two-model autoregressive cascade by 1. generating audio given the script and possibly other user-provided controls and 2. generating video from this audio. All the things that make a performance feel authentic—the speaker’s identity, language, accent, emotion, and environmental context—are learned by the audio model and inherited by the video model, as captured by the term p(v | a, t, c).
When creating content that is expressive, realistic, and faithful to input controls, users may find themselves tuning and re-running the generation flow to iteratively refine the end product towards their desired outcome. This process can be costly and time-consuming, especially when generating audio and video in tandem.
By simply allowing users to tune the audio of a generated performance first, we enable a significantly tighter feedback loop, creating a far more efficient and interactive product experience. This is because the cost of audio and video is rather asymmetric—video is several orders of magnitude heavier than audio, which corresponds to a correspondingly higher inference cost. For example, 30 seconds of high-definition video (720p at 24fps) contains approximately 2 billion floating-point values, whereas CD-quality audio (single-channel at 44100Hz) comes in at around 1.5 million—video is over 1000x larger!
Design principles
Mirage audio is a latent audio diffusion model built on the same multimodal Mochi Transformer architecture we used for Mirage video. Mirage audio is trained via flow-matching diffusion to generate audio waveform latents, and generated latents are decoded directly to 44.1kHz mono audio. No spectrograms were harmed during variational autoencoder (VAE) or base model training. Because Mirage audio shares the same base architecture and training paradigm as our video model, we were able to stand up a strong audio model in months.
The model is conditioned on input text that represents both 1. the target script for one or more speakers in any Unicode character set (allowing the model to generate audio in many languages), and 2. a description of the acoustic, semantic, and performative characteristics of the target audio. For voice cloning and voice tuning settings (described below), the model is also conditioned on reference audio that is mapped into the same latent space as the generated latents.
As with Mirage video, all input embeddings are processed with all-to-all self-attention and modality-specific multi-layer perceptrons (MLPs). This produces a model block that can be interpreted as a kind of Mixture-of-Experts (MoE) block with hard-coded, modality-specific routing:
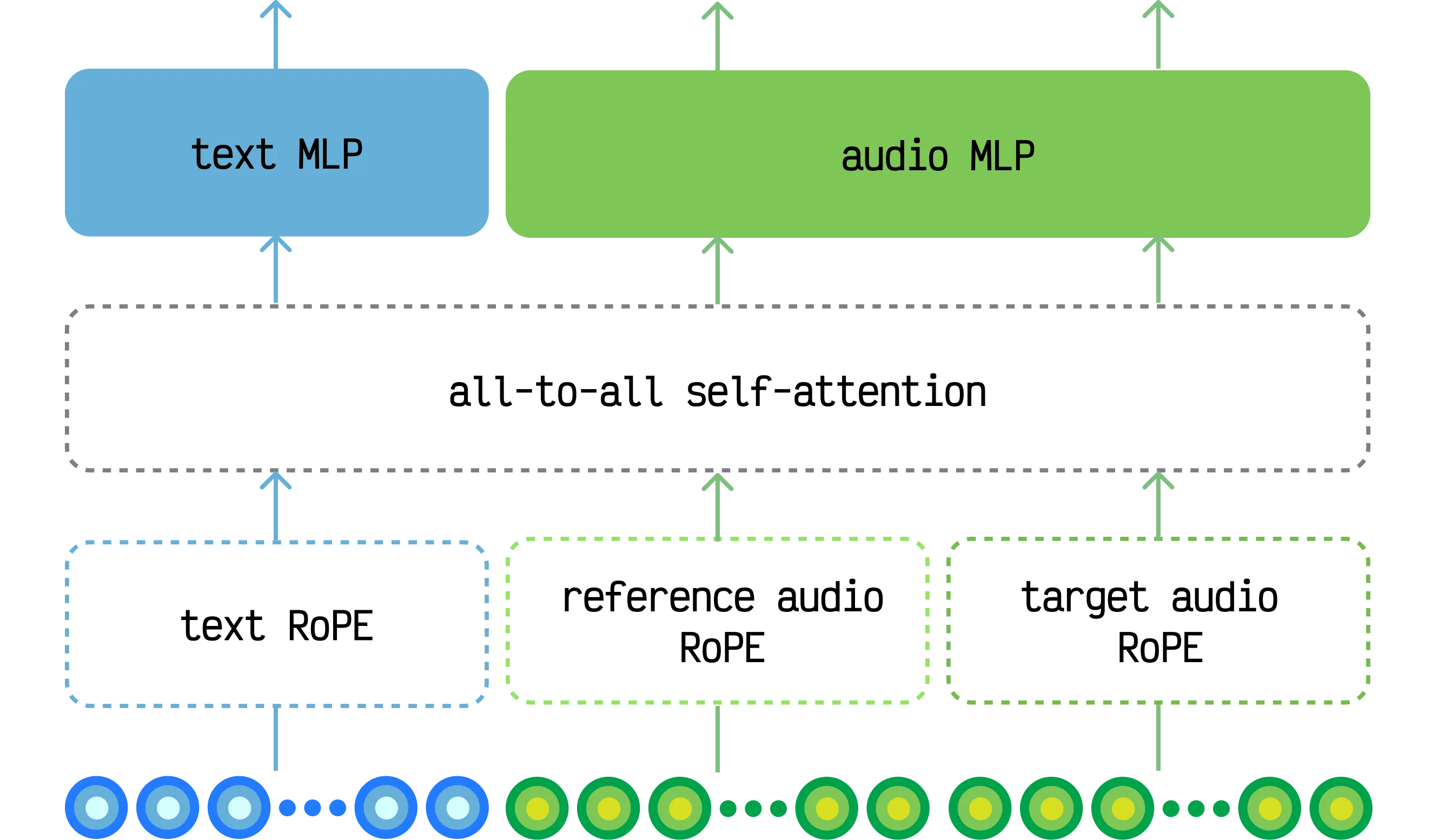
Because the architecture uses a general purpose design with minimal domain-specific inductive biases, the model learns to generate high quality audio containing speech, ambience, foley, sound effects, music, and everything in between.
Shaping expressive performances
With Mirage audio, users can 1. design and shape voices and soundscapes from scratch (voice design), 2. create new performances using their own expressive voice (voice cloning), and 3. reimagine familiar voices in new settings, new languages and accents, or different emotions or performative targets (voice tuning).
We show samples generated by the model using these three methods below.
1. Voice design: Design and shape voices and soundscapes from scratch
Mirage audio allows users to generate audio with realistic or fantastical voices in a wide variety of settings and emotional contexts.
Knight delivering an epic speech:
Scared woman in a horror movie:
American man at the seashore:
British sci-fi spaceship alarm system:
2. Voice cloning: Create a new performance using an input voice
Mirage audio preserves the identity of input audio, including details of localized accents and the idiosyncratic delivery and pronunciation of each person’s speaking style.
Woman with Indian English accent
Mirage audio:
Source:
Man with British English accent
Mirage audio:
Source:
Same script, different speaker identities
Identity A | Identity B | Identity C | |
|---|---|---|---|
Source audio | |||
Target script 1 | |||
Target script 2 |
3. Voice tuning: Reimagine a familiar voice in a new setting, in a new language and accent, and with any emotion or performative target
Mirage audio can also transform audio while preserving vocal identity. This opens up applications including improving the quality of a noisy recording, making it sound like a speaker was recorded in a different environment, and even dramatically changing the accent and performance style of the speaker.
Cleaning up a low-quality recording and adding a piano
Mirage audio:
Source:
Location change: Moving a voice to a busy conference center
Mirage audio:
Source:
Dramatic transformation: Voice to karaoke singer
Mirage audio:
Source:
Mirage audio is available now
Our first Mirage audio release focuses on the model’s voice cloning capabilities. With voice clone in Captions, you can replicate an original audio source while preserving the voice’s identity including its accent. Mirage even makes it possible to believably extend the voice’s identity into new languages or accents.
Cloned voices carry over the same energy, expressions, and emotion as the source audio, opening new possibilities for AI audio. It’s simple to clone once, and then use that same audio recording to generate new videos over time.
To try it for yourself, go to the Captions “Voices” page and start a new voice clone. Then, switch the audio model to “Mirage.”
What’s next
We built the initial version of Mirage audio with limited time, data, and compute to establish a foundation for continued research and product progress. Future research efforts on model quality and efficiency will unlock even better capabilities in generating high-quality audio and more control in quickly shaping realistic, compelling performances. Mirage is committed to giving users full control over the video creation stack, from shaping voices and generating video to refining edits.
The future of audio generation is controllable, multimodal, and focused on real user needs. Watch this space to always have the latest updates.
Acknowledgments
Research and engineering contributors to Mirage audio: Aditi Sundararaman, Aggelina Chatziagapi, Ameya Joshi, Amogh Adishesha, Andrew Jaegle, Dan Bigioi, Hyoung-Kyu Song, Jon Kyl, Justin Mao, Kevin Gu, Kevin Lan, Mojtaba Komeili, ShahRukh Athar, Sheila Babayan, Stanislau Beliasau, and Stephan Brezinsky.
This work would not have been possible without the engineering and product contributions of Alex Du, Amar Patel, Amber Shi, Dan Noskin, Gaurav Misra, Jason Silberman, Sam Resendez, and many others at Mirage.
